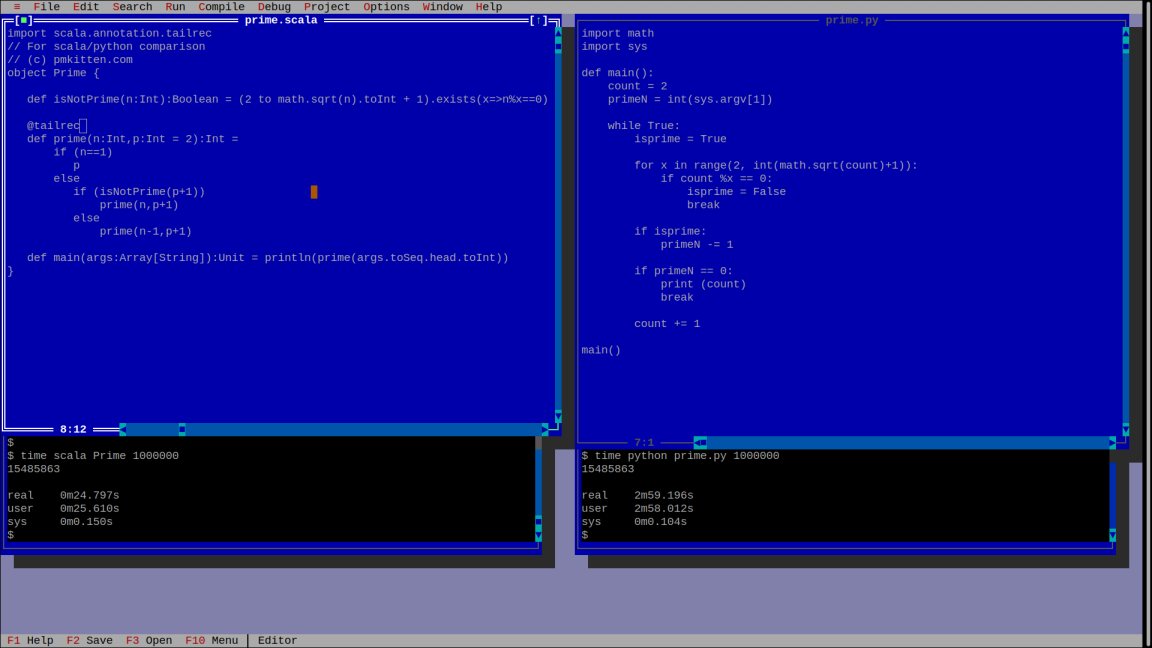
Native scala.
Думаю, что каждый, кто знаком и со скалой и с питоном замечал, что скала работает намного быстрее, чем питон, а программировать сложные алгоритмы на языке скала проще, так как не приходится избавляться от хвостовой рекурсии, добавляя чисто технические переменные управления циклом, либо используя батутную реализацию хвостовой рекурсии.
В то же время, скала - это не просто оболочка над JVM - это полноценный язык, который имеет реализацию для JavaScript (scala.js) и для llvm (native scala)
Попробуем запустить простенькую программу в бинарном режиме на scala и сравнить её с программой на scala работающей в JVM.
В качестве подопытного кролика возьмём алгоритм из https://pmkitten.com/why
Что мы имеем:
Реализация на scala отрабатывает для 1000000 за 24 секунды вместе с запуском среды исполнения, реализация на питоне за 3 минуты.
Теперь то же самое с native scala
1. ставим clang:
sudo apt install clang
2. создаём проект scala native
sbt new scala-native/scala-native.g8
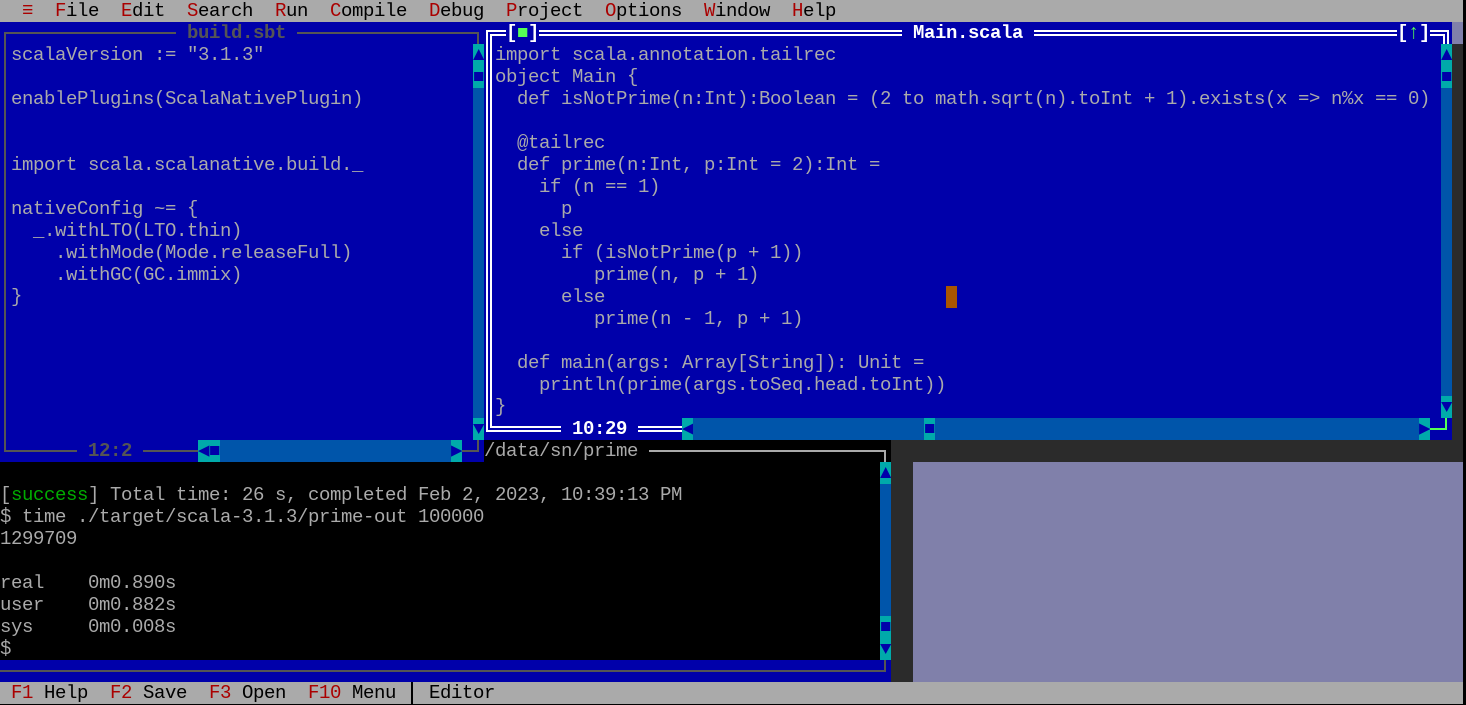
Далее перебиваем текст с картинки в файл Main.scala и выполняем сборку бинарника
sbt nativeLink
И получаем, сначала для 100000
time ./target/scala-3.1.3/prime-out 100000 1299709real 0m6,376s user 0m6,372s sys 0m0,004s
В то же время, для JVM реализации время будет в 6 раз меньше:
time scala Main 100000 1299709real 0m0,663s user 0m0,912s sys 0m0,053s
получаем: -- время выполнения для бинарника scala native для 100000-чного числа время выполнения 6 секунд, -- а для scala, работающей поверх jdk 17 0.6 секунд, то есть, в 10 раз быстрее.
Для 1000000 уже не имеет смысла гонять программу - и так всё понятно, что JVM победит.
Получили результат, в два раза более медленный, чем в питоне.
Попробуем поправить sbt
Для 100000 результат уже лучше - приближен к JVM, и намного лучше питона. Теперь можно попробовать и для 1000000:
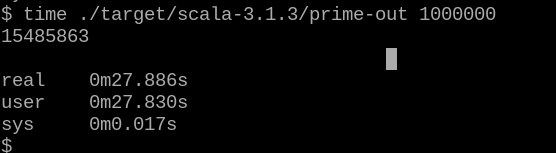
Всё равно медленее, чем JVM, но это уже терпимо.
Таким образом, рекорд быстродействия связки Scala и JVM не побит, но полученный результат показывает, что это не питон так сильно тормозит - это Scala на JVM так быстро работает. Так что не зря для реализации алгоритмов обработки больших данных используется именно она, а не питон, который служит, скорее запускалкой алгоритмов.
И видно, что не всё нативное быстрое.
Это следует понимать и сторонникам реализации математических алгоритмов на чистом C для подключения их к питону.
Вы реально уверены, что с вашей нативной реализацией не повторится та же самая история, что мы наблюдаем с нативной реализацией от native scala?
Однако, у нативного варианта есть и преимущество - памяти он занял для работы всего 8 мегабайт, а для скалы на JVM потребовалось 80 мегабайт, то есть, в 10 раз больше.
Это может быть полезно при запуске на хостинге с малым объёмом памяти.
Написано на Dotty и Wicket
!без Web 2.0!
Адаптировано для работы в Lynx
канал в Дзен