Dotty это новая версия языка scala - scala 3.0.
Для этой версии даже придумали новое название языка - Dotty вместо Scala. Новое название говорит о новых возможностях и особенностях версии, которые могут привести к несовместимости кода и библиотек с уже существующими версиями языка.
Однако, большинство библиотек для анализа данных, в том числе graphx и sparkml, написаны ддя проекта спарк, и возникает закономерный вопрос - возможно ли их использовать из Dotty?
В настоящее время сборки спарка, которые поставляют крупные компании, собраны для scala 2.11 или 2.12, и при использовании их из Dotty могут возникнуть проблемы. Но для задач процессной аналитики нет никакого смысла использовать уже собранные версии библиотек фреймворка.
Всегда можно взять ветку master от спарка и поменять зависимости. Но на что их лучше менять? Известно, что Dotty полностью бинарно совместим со Scala 2.13.5, а последняя версия Scala 2.13.7
Если выкачав ветку master из гита мы начнём менять зависимости, то увидим что в pom-нике уже есть профиль с названием scala-2.13.
Если выполнить компиляцию с использованием этого профиля и поменять в pom.xml scala.version на 2.13.7, то получим бинарник, работающий с версией 2.13.7. Интересно, что ветка spark_3_3 с 2.13.7 не рабтает - в этой версии более строгие ограничения на использование скобок при вызове функций, которые учтены только в ветке master.
Если будут проблемы с компиляцией ветки мастер с использованием профиля - можно просто отредактировать pomники, чтобы библиотеки scala-2.13 подсоединялись всегда. Это командой:
find . -name pom.xml | xargs sed -i '/if.*scala-2.13/d'и последующим редактированием scala.version в помнике проекта
Таким образом, свежие версии библиотек спарка могут быть скомпилированы со скалой 2.13.7 и использоваться в scala 3.0
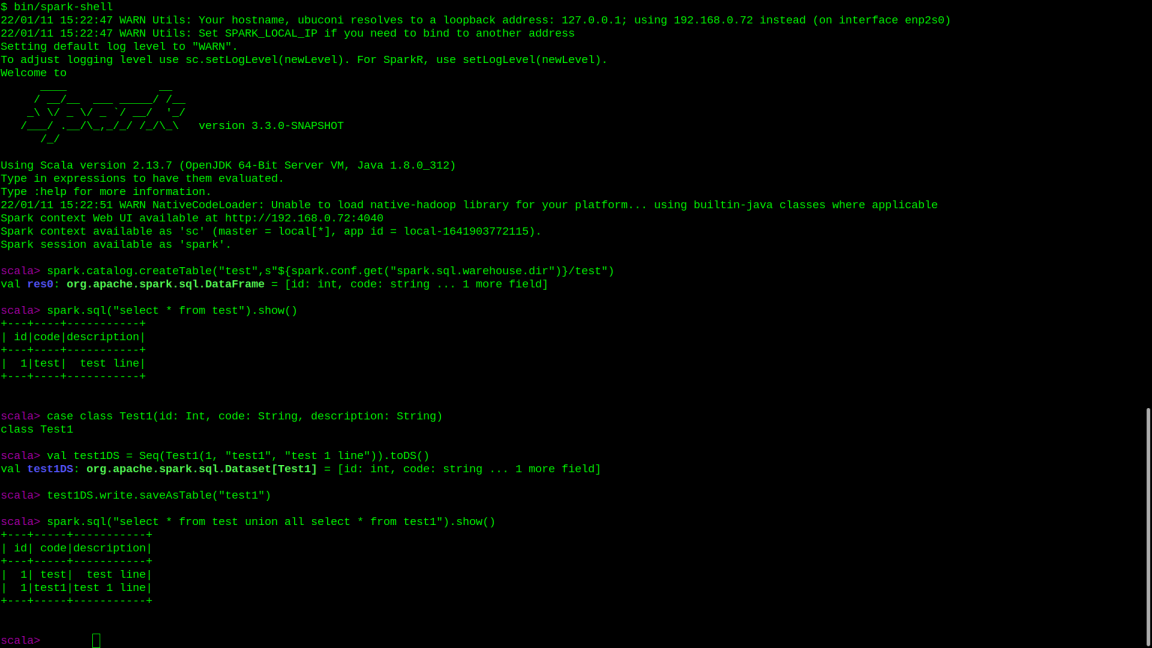
Обычно спарк работает поверх hive, от которого требуется хранилище метаданных для таблиц и hiveQL. Но hiveQL для большинства задач не нужен и только вредит, если есть уже Spark SQL и API работы с DataFrameами, а вот хранить метаданные таблиц спарк умеет только в двух хранилищах - в памяти и в хайве.
Когда метаданные таблиц хранятся в памяти, то они исчезают с завершением сессии. Однако, их можно добавить обратно с помощью метода createTable из catalog'а
spark.catalog.createTable("test",s"${spark.conf.get("spark.sql.warehouse.dir")}/test")Сохранить же данные в таблицу с отвутствии hive'а можно стандартным методом saveTableAs (если таблица новая) или insertInto (если существующая)
Таким образом, новые версии спарка совместимы по бинарному коду со scala 3.0 (так как основаны на совместимой версии scala), могут использовать джарники от scala 3.0 и могут использоваться из джарников в scala 3.0
Это даёт возможность простого деполоя заданий процессной аналитики (при выносе их в либы на скале) на любой вид кластера, поддерживаемого спарком - standalone (запущенные на нодах сервисы, ждущие задач), yarn или kubernetes, что позволяет добиваться масштабируемости при росте в обрабатываемых журналах числа CASE_ID путём партиционирования расчёта по CASE_ID на этапах расчёта, допускающих такое партиционирование.
Написано на Dotty и Wicket
!без Web 2.0!
Адаптировано для работы в Lynx
канал в Дзен